
🏴🇬🇧 Curating a Welsh-English Translation Dataset for language models
Modern large language models have strong multilingual capabilities, but languages with a small digital footprint on the internet, like Welsh, remain underserved. This matters: as AI becomes more prevalent, poor support for these “low-resource” languages creates a digital divide with minority communities and risks reducing the language’s active use over time.
Post-training (instruction tuning) offers a path to improve low-resource language performance, but it requires structured input-output pairs. Translation is an ideal task for this: parallel corpora provide natural instruction-response pairs, and the task itself reinforces the model's understanding of the language.
Welsh (Cymraeg) is spoken by over 800,000 people [1], and the Welsh Government's Cymraeg 2050 strategy aims to reach one million speakers by 2050 [2], making language technology an important part of this vision. However, available data in Welsh is scattered across sources with varying quality, containing noise, duplicates and artifacts that degrade model performance during fine-tuning.
At Locai Labs, we're building language models that work for everyone, not just speakers of the most common languages. As part of this mission, we're excited to release a comprehensive Welsh-English parallel corpus designed specifically for post-training language models. This dataset combines multiple high-quality sources and applies rigorous quality filtering to create a robust training resource for the Welsh language community. Our model Locai L1-large was trained on low-resource language datasets curated using similar pipelines and our hope for this dataset is for it to be used to improve Welsh capabilities in language models globally and serve as a benchmark for translation quality research in low-resource settings. The dataset is available on Huggingface at: locailabs/welsh-english-parallel-translations.
Methodology
Data sources
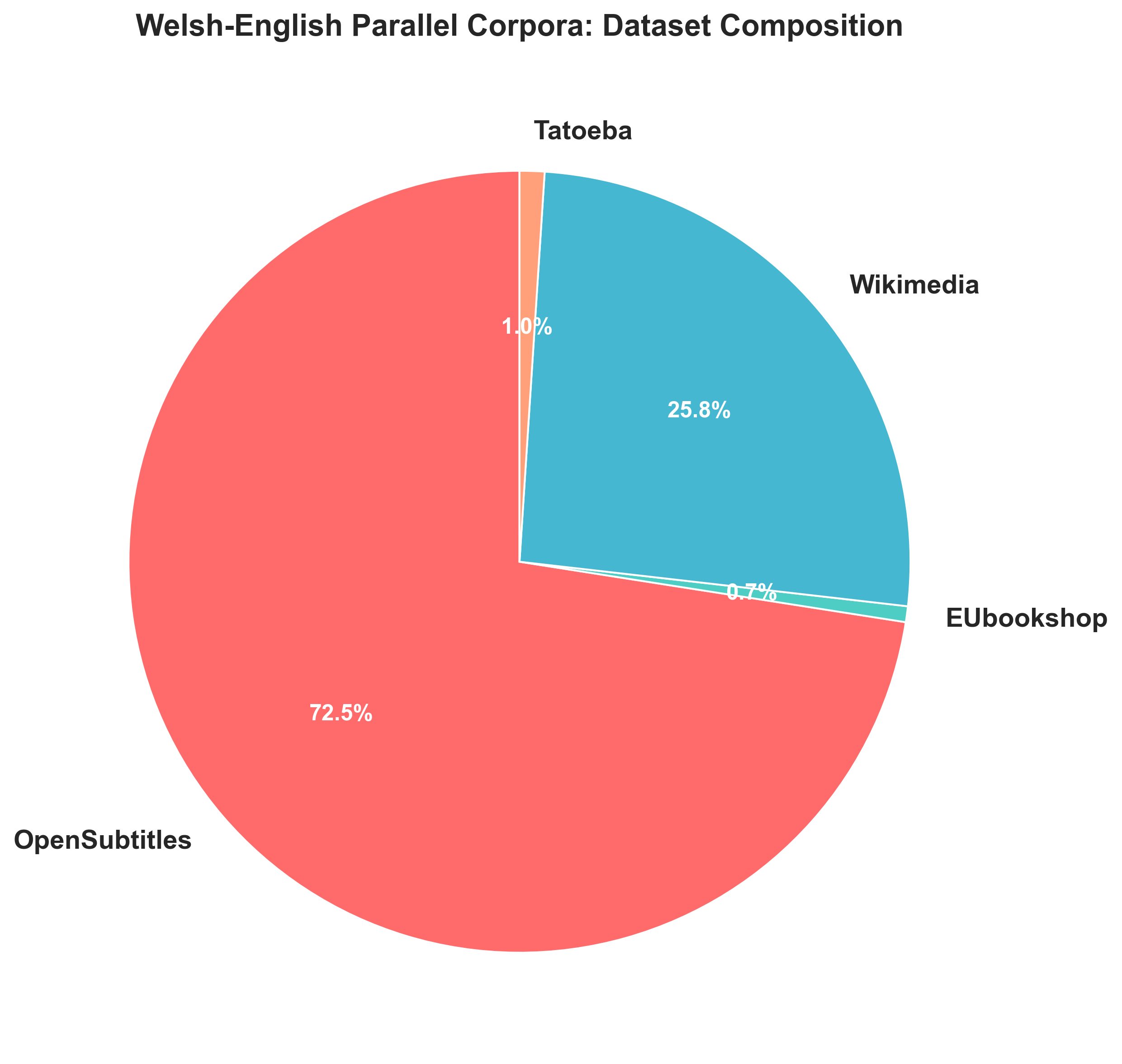
We aggregated Welsh-English translation pairs from four corpora via the OPUS project [3]:
- OpenSubtitles [4]: conversational dialogue from movies and TV
- Wikimedia [5]: pairs of encyclopaedic content from Wikipedia translations
- EUbookshop [6]: pairs of technical language from EU documents
- Tatoeba [7]: community-contributed sentences
This gives the corpus coverage across conversational, encyclopaedic, technical, and informal registers.
Processing Pipeline
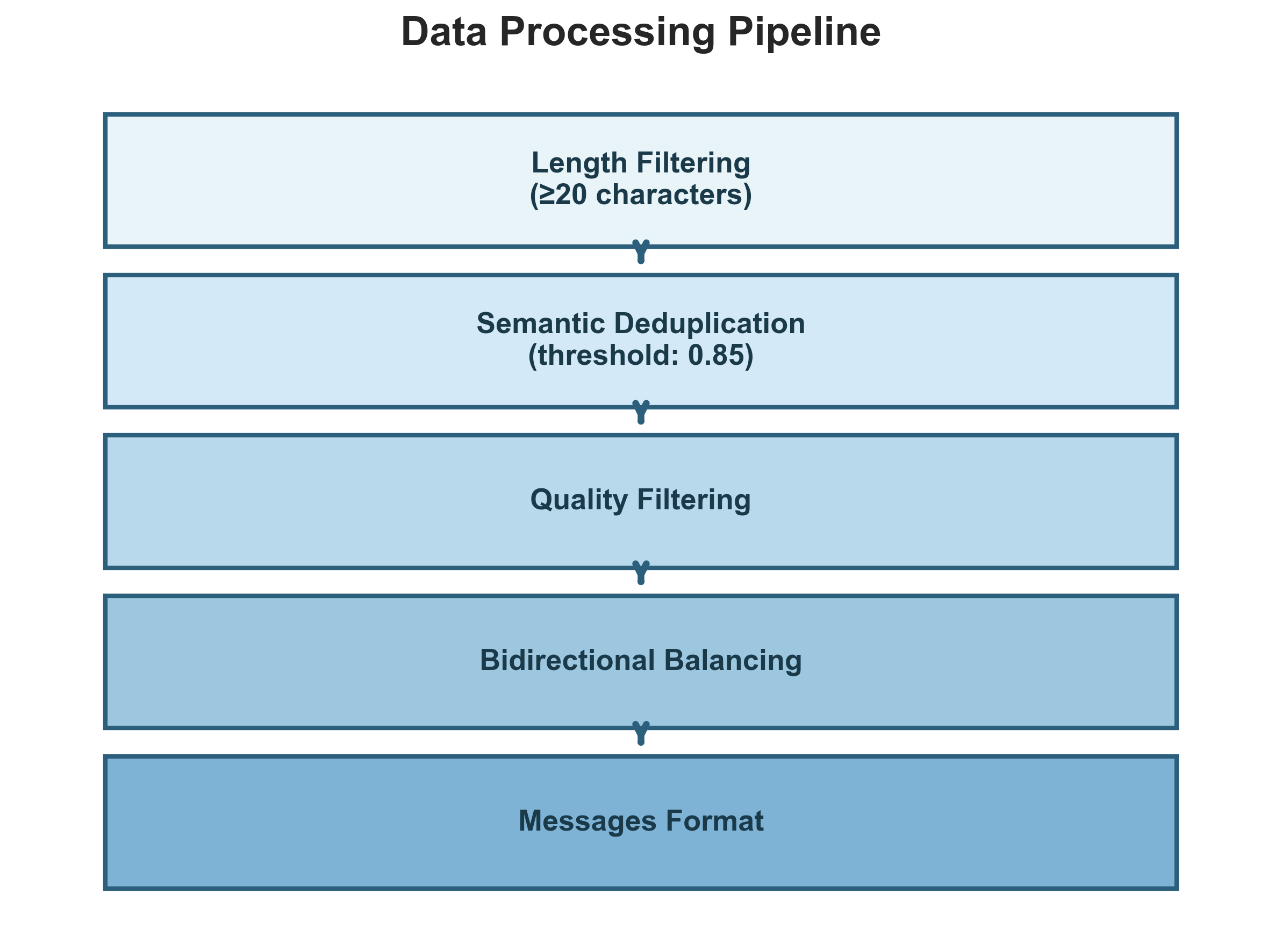
Raw parallel corpora contain significant noise. We implemented a four-stage processing pipeline:
- Length filtering: Remove pairs where either side is fewer than 20 characters, eliminating low-information exchanges like "Yes" or "Thanks".
- Semantic deduplication: Subtitle data is highly repetitive, characters say "I don't know" countless times across films. We use MinHash LSH with multilingual sentence embeddings (`paraphrase-multilingual-MiniLM-L12-v2` [8]) at a 0.85 similarity threshold to catch near-duplicates that exact string matching would miss.
- Quality filtering: Remove pairs containing URLs, emojis, and excessive repetition (e.g., "aaaaaaa" or repeated words), typically formatting artifacts rather than natural language.
- Bidirectional balancing: Split the dataset equally between English→Welsh and Welsh→English directions.
Dataset format
Each entry follows the messages format standard for instruction fine-tuning:
{
"messages": [
{
"role": "user",
"content": "Translate the following English text into Welsh:\n\nGood morning, how are you?"
},
{
"role": "assistant",
"content": "Bore da, sut wyt ti?"
}
],
"source_dataset": "OpenSubtitles"
}
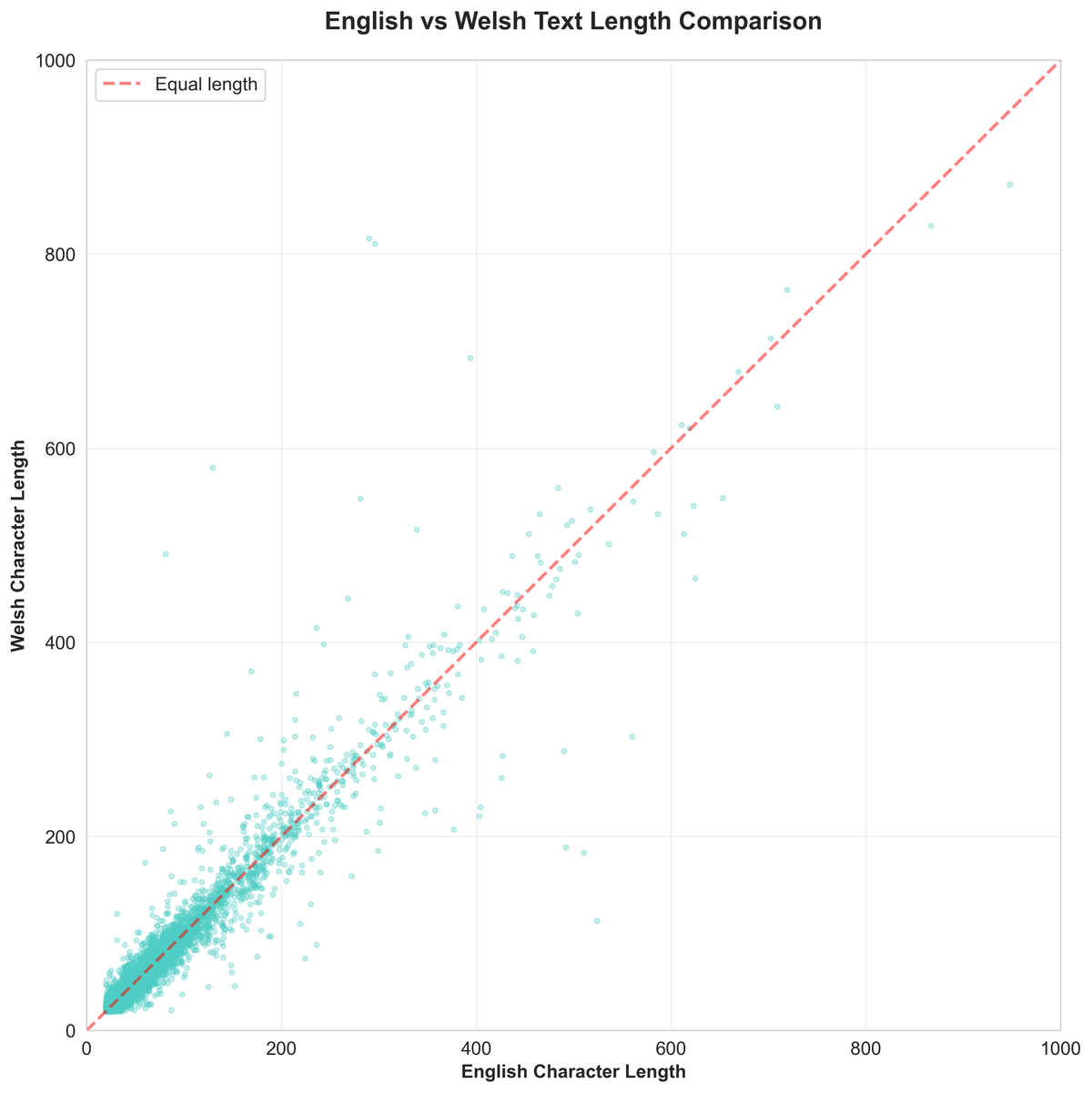
The `source_dataset` field enables domain-specific analysis. Text lengths are well-balanced across both languages.
Future work
We're exploring additional languages and data sources (news articles, government documents), planning human evaluation of translation quality, and developing multilingual benchmarks.
Acknowledgements
This work builds on the OPUS project [2], the OpenSubtitles community [4], Wikimedia Foundation [5], Tatoeba [7], and EU Bookshop [6].
References
[1] Welsh Government. (2025). *Welsh language data from the Annual Population Survey: October 2024 to September 2025*. https://www.gov.wales/welsh-language-data-annual-population-survey-october-2024-september-2025-html
[2] Welsh Government. (2017). *Cymraeg 2050: A million Welsh speakers*. https://www.gov.wales/cymraeg-2050-welsh-language-strategy
[3] Tiedemann, J. (2012). Parallel Data, Tools and Interfaces in OPUS. In *Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012)*.
[4] Lison, P., & Tiedemann, J. (2016). OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In *Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC 2016)*.
[5] Wikimedia Foundation. *Content Translation parallel corpus*. https://dumps.wikimedia.org/other/contenttranslation/
[6] Skadiņš, R., Tiedemann, J., Rozis, R., & Deksne, D. (2014). Billions of Parallel Words for Free: Building and Using the EU Bookshop Corpus. In *Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC 2014)*.
[7] Tatoeba. (2024). *Collection of sentences and translations*. https://tatoeba.org/en/
[8] Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In *Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing*.
Citation
@dataset{drayson2026welsh,
title = {Welsh-English Parallel Corpora: A High-Quality Translation Dataset},
author = {Drayson, George},
year = {2026},
publisher = {HuggingFace},
organization = {Locai Labs},
url = {https://huggingface.co/datasets/locailabs/welsh_parallel_corpora}
}



